依赖性与条件概率
色盲是 X 染色体上的基因缺陷引起的,由于男性只有一条 X 染色体,而女性有两条 X 染色体。因此男性更容易受到 X 染色缺陷的不良影响,从而患有色盲的概率大概是女性的 16 倍。
因此,整个人群中色盲率是 4.25%,但女性是 0.5%,男性是 8%。
假设人群中,男女比例为 5050,用条件概率来表示则是:
P(色盲)=0.0425
P(色盲∣女性)=0.005
P(色盲∣男性)=0.08
如果随机选择一个人,他是男性色盲的概率是多少?
根据概率的乘法原则,
P(男性,色盲)=P(男性)×P(色盲)=0.5×0.0425=0.02125
如果同样计算女性色盲的概率:
P(女性,色盲)=P(女性)×P(色盲)=0.5×0.0425=0.02125
这不可能是对的,因为我们已经知道女性患有色盲的概率比男性低很多。
乘法法则只有事件独立的时候才有效,而性别和患有色盲症并不是独立的事件。
因此,男性色盲出现的真正概率是男性出现的概率乘以他是色盲的概率。
P(男性,色盲)=P(男性)×P(色盲∣男性)=0.5×0.08=0.04
那么乘法法则可以拓展为:
P(A,B)=P(A)×P(B∣A)
对于独立事件来说,P(B)=P(B∣A)。
同样加法原则也可以定义为:
P(A∪B)=P(A)+P(B)−P(A)×P(B∣A)
逆概率与贝叶斯定理
条件颠倒过来计算其依赖事件的概率,也就是可以通过 P(A∣B) 计算出 P(B∣A)。
假设你正在给一家色盲矫正眼镜公司的客服代表发送电子邮件。这款眼镜有点贵,于是你在邮件中说自己担心眼镜可能不起作用。客服代表回复说:“我也是色盲,我自己也有一副,效果非常好!”
我们想知道这位客服代表是男性的概率,但是除了工号之外,这位客服代表没有提供任何其他信息。那么,怎样才能算出这位客服代表是男性的概率呢?
直觉上,我们认为客服代表是男性的可能性更大,但这需要量化才能确定。
为了便于分析,我们假设人群总数是 N,那么:
P(男性∣色盲)=P(色盲)×N?
下一步需要计算出人群中男性色盲的人数。这很简单,直接用男性色盲概率乘以总人口就可得出:
P(男性)×P(色盲∣男性)×N
因此,在已知客服代表患有色盲症的情况下,他是男性的概率是:
P(男性∣色盲)=P(色盲)×NP(男性)×P(色盲∣男性)×N
将 N 约掉后就得到:
P(男性∣色盲)=P(色盲)P(男性)×P(色盲∣男性)
现在我们可以直接求解这个问题了,代入数据,可计算出这位客服代表是男性的概率高达 94.1%。
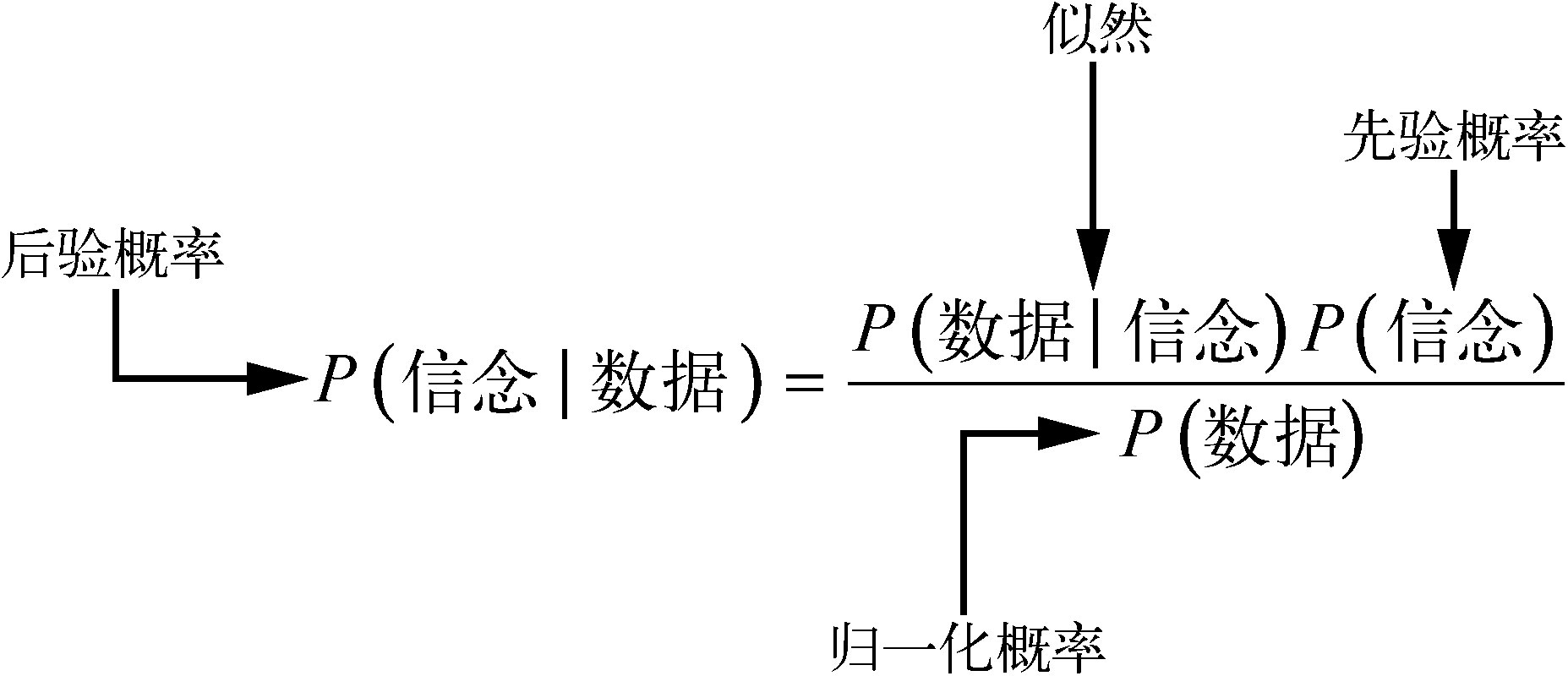
贝叶斯定理
将前面的计算推广到通用的事件 A 和 B,就可以得到贝叶斯定理。
P(A∣B)=P(B)P(A)×P(B∣A)
三要素
贝叶斯定理可以准确地量化所观察到的数据改变我们信念的概率。简单来说,我们想量化的是:在所观察到的数据下,自己对信念的坚信程度。
在贝叶斯公式中,这个要素的术语是后验概率(posterior probability,简称为“后验”)。
为了得到后验概率,还需要用到下一个要素:似然(likelihood)。它表示在给定信念的情况下,观察到某一数据的概率,P(数据∣信念)。
最后,需要量化初始信念的概率,即 P(信念)。这一要素在贝叶斯定理中被称为先验概率(prior probability,简称为“先验”),它表示我们在看到数据之前的信念强度。
通常情况下,我们需要使用数据的概率 P(数据) 对后验 归一化(贝叶斯定理的分母),从而使其值介于 0 和 1 之间。在实践中并不总是需要 P(数据),所以这个值没有特殊的名字。
调查犯罪现场
假设,有一天下班回家,你发现家里的窗户玻璃碎了,前门开着,笔记本电脑不见了。你的第一反应大概是“家里被盗了!”
这里我们的假设 H=被盗,我们需要一个概率来描述家里被盗的概率有多大。
根据现有的数据,我们想要求解的后验概率是:
P(被盗∣窗户玻璃碎了,前门开着,笔记本电脑不见了)
求解似然
在这个例子中,如果家里真的被盗了,同样的数据会被观察到的概率。换句话说,数据与假设的吻合程度:
P(窗户玻璃碎了,前门开着,笔记本电脑不见了∣被盗)
被盗时以上所有数据并非都存在的任何场景。例如,聪明的小偷可能撬开了你家的锁,偷走笔记本计算机之后再把门锁上,这不需要打破窗户玻璃。或者他可能只打破了窗户玻璃,拿走笔记本计算机之后再通过窗户爬出来。
我们假设被盗时只有 103 会出现这些数据。
先验概率
接下来,我们需要确定家里被盗的概率。这也是本例的先验概率。先验概率非常重要,因为它允许我们使用背景信息对似然进行调整。
例如,如果你家位于犯罪率很高的街区,那么盗窃事件就可能会经常发生。为简单起见,我们将被盗的先验概率设定为:
P(被盗)=10001
请记住,如果有不同的或额外的数据,随时可以调整这个概率。
这样我们就有了 未归一化 的概率:
P(被盗)×P(窗户玻璃碎了,前门开着,笔记本电脑不见了∣被盗)=100003
归一化数据
在这个例子中,我们还需要这些数据发生的概率 P(D),无论家里是否被盗。换句话说,无论有没有被盗,“窗户玻璃碎了,前门开着,笔记本电脑不见了”发生的概率。
P(被盗∣窗户玻璃碎了,前门开着,笔记本电脑不见了)=P(D)103×10001
| P(D) | 后验概率 |
|---|
| 0.050 | 0.006 |
| 0.010 | 0.030 |
| 0.005 | 0.060 |
| 0.001 | 0.300 |
可以发现 P(D) 越小,后验概率越大。也就是说,数据出现的可能性越小,事件发生的可能性就越大。
假设你的朋友是百万富翁只有通过两种方法,一种是买彩票中奖,一种是继承某个亲戚的遗产。你朋友成为百万富翁的概率非常小。如果你知道你朋友变成百万富翁了,那么他买彩票中奖的概率就会变大。
P(D) 最常见的问题是在很多现实情况下,它很难精确计算。
好消息是,在某些情况下,并不需要明确知道 P(D) 的值,因为我们通常只是想对假设进行比较。
备择假设
现在提出另外一个假设,并将它与原来的假设进行比较。新假设包括以下 3 个事件:
- (1) 邻居家孩子把棒球打到了窗户上
- (2) 你离开家时忘了锁门
- (3) 你忘了自己带笔记本计算机去上班并把它落在了办公室
我们用事件前面的编号来指代这些事件,并将它们统称为 H2,所以 P(H2)=P(1,2,3)。
备择假设的似然
对似然,我们想计算的是在给定假设下所观察到的事件的概率,或者说是 P(D∣H2)。在这里,P(D∣H2)=1。
如果假设中的所有事件都发生了,那么你肯定会观察到窗户玻璃碎了、前门开着以及笔记本计算机不见了。
备择假设的先验概率
我们假设每个可能的结果都是条件独立的。
备择假设的第一项内容是,邻居家孩子打棒球时不小心打碎了窗户玻璃。虽然这在电影中很常见,但现实中我从未听说过这种情况,更多的情况是发生了盗窃,所以我们假设棒球打碎窗户玻璃的概率是被盗概率的一半:
P(1)=20001
备择假设的第二项内容是你忘了锁门。这种情况相当普遍,所以假设它每月发生一次:
P(2)=301
虽然带着笔记本计算机去上班并将它落在办公室可能很常见,但完全忘记带着它去上班的情况不太常见。
假设这种情况每年会发生一次:
P(3)=3651
那么基于乘法法则:
P(H2)=20001×301×3651=219000001
所以,三个条件同时发生的概率很小。
备注假设的后验概率
我们知道似然 P(D∣H2) 等于 1,所以如果第二个假设是真的,那么我们就一定会看到这些数据。
如果没有先验概率,看起来这个新假设的后验概率要比原假设(家里被盗了)恰当得多,因为即使被盗了,我们也不太可能看到这些数据。
P(D∣H2)×P(H2)=1×219000001=219000001
比较非归一化的后验概率
我们需要求出两个后验概率的比值。比值能够告诉我们一个假设的可能性是另一个假设的多少倍。
将原假设定义为 H1,这两个假设为真的概率之比:
P(H2∣D)P(H1∣D)
使用贝叶斯定理将每一项展开:
P(H2)×P(D∣H2)×P(D)1P(H1)×P(D∣H1)×P(D)1
分子和分母都有 P(D)1,意味着可以直接消去保持不变,这就是比较假设时 P(D) 并不重要的原因。
代入数值:
P(H2)×P(D∣H2)P(H1)×P(D∣H1)=219000001100003=6570
这意味着 H1 对观察到的数据的解释能力是 H2 的 6570 倍。
换句话说,我们的分析表明,原始假设 H1 比备择假设 H2 更能解释所观察的数据。
这也符合我们的直觉:根据观察到的场景,被盗看起来更可能是事情的真相。
我们想用数学方式表达非归一化后验概率的性质,可以用下面版本的贝叶斯定理:
P(H∣D)∝P(H)×P(D∣H)
其中,∝ 意思是“成正比”。
这个公式可以理解为“后验概率,即给定数据下假设的概率,与 H 的先验概率和在假设 H 下数据概率的乘积成正比”。
想要比较两个假设的概率,但 P(D) 又不容易计算的情况下,贝叶斯定理的这种形式就非常有用。对假设进行比较,就意味着我们可以确切地知道一种假设对观察内容的解释要比另外一种假设的可信度强多少。